Is Artificial Intelligence Suitable to Solve Cain’s Jawbone? (Part I)
All opinions herein are solely my own and do not express the views or opinions of my employer. This article contains a potential solution to Cain’s Jawbone. If you plan to solve it by yourself, stop reading it.
We suggested a solution to Cain’s Jawbone as a personal project almost a year ago.
Cain’s Jawbone, by Edward Powys Mathers, is a puzzle consisting of 100 shuffled pages. To manually solve it, the following heuristic was used:
Group the pages by narrators (there are eight of them, concealed in the narration).
Then, sort the pages in each group.
Last but not least, sort the groups themselves.
Now, we would like to investigate whether artificial intelligence (in a broad sense) could be used to find a solution more efficiently, at least partially. We are only at the very beginning of this analysis.
We initially considered leveraging NLP to detect the hidden patterns connecting the pages. However, initial investigations quickly highlighted that Mathers heavily used extratextual clues (hidden quotes, sequence of train stops between two stations, etc.). Consequently, the process leading to the solution was not automated: the pages were grouped and sorted using intratextual clues as well as references to the outside world. We only developed an ad hoc tool to cross-reference the pages against books in the public domain to detect hidden quotes.
To begin our analysis of the suitability of artificial intelligence, we have opted for a classic unsupervised learning approach (word vectorization and k-means clustering) to group the pages automatically by narrators. Indeed, given the characteristics of the data (small dataset, no clear way to label the pages, ...), supervised learning is not necessarily the most relevant.
We anticipated that the result would be limited because of (a) the extratextual clues, (b) the simplicity of our approach—at this stage, at least—, and (c) the fact that the pages were all written by the same person pretending to be eight different narrators (meaning that the style difference between the pages is artificial, not intrinsic). To our surprise, while the clusters do not greatly overlap the expected groups (even though k is set to the actual number of narrators), the representation of the PCA reduction of naive k-means clustering revealed an “affinity” between some of the pages which is more or less in line with the expected solution. This is particularly true for Bill Hardy and Henry the dog.
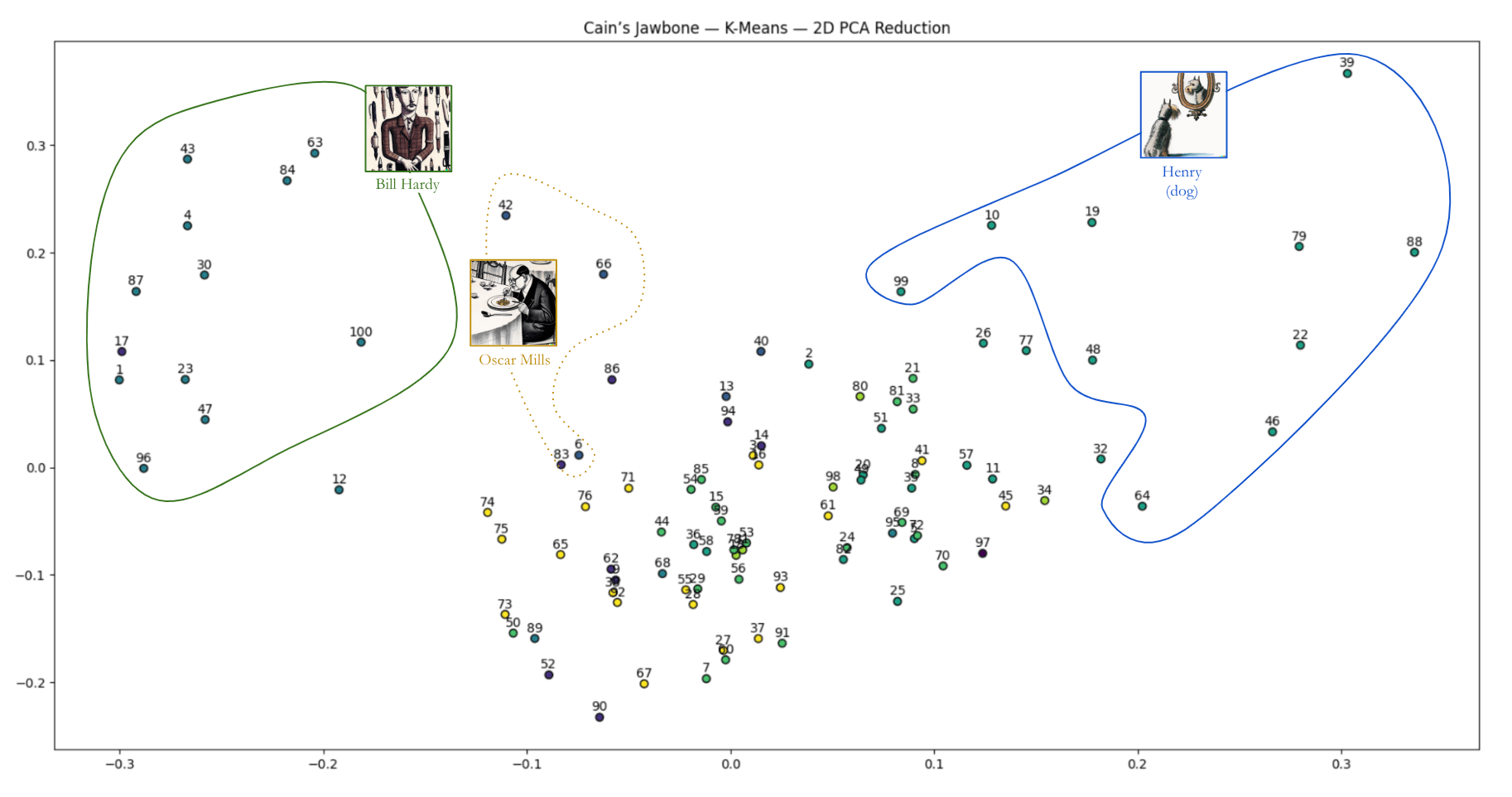
These preliminary results tend to indicate that NLP may be suitable, to some extent, to identify the narrators. To that end, it will need to be improved to use additional clues and automatically determine the number of narrators (we tried to use the elbow method to that end, but as it was inconclusive in the context of this preliminary analysis, and therefore had to specify this number ourselves).
If the use of artificial intelligence succeeds in identifying the underlying narrators, we will continue our investigation to see to what extent it could sort the pages in each group.