Is Artificial Intelligence Suitable to Solve Cain’s Jawbone? (Part II)
All opinions herein are solely my own and do not express the views or opinions of my employer. This article contains a potential solution to Cain’s Jawbone. If you plan to solve it by yourself, stop reading it.
Previously, we wondered about the relevance of using artificial intelligence to solve Cain’s Jawbone. On this occasion, a naive K-means clustering had revealed that some of the pages had some affinity with each other, paving the way for the autodiscovery of narrators.
Because a potential and unofficial solution is known, pages can be labeled, enabling supervised learning.
Initially, we were reluctant to do it for the several reasons. First, the dataset is minimal (only 100 pages) and not extensible: was it worth the trouble to train a model that would ultimately be used only once? Second, the differences between the narrators are essentially extratextual and fictitious (the narrators are a fiction created by the same writer): would a model identify hidden reliable criteria to characterize a narrator? Last but not least, the solution has not been made official: do we risk using erroneous labels?
But to our surprise, the supervised learning approach produces actionable results.
We fine-tuned a BERT (base, uncase) model to perform a classification. Before considering a multiclass classification (one output neuron per narrator), we have more modestly operated a binary classification (one output neuron) to identify whether a given page belongs to Bill Hardy—the narrator the most evidently isolated by the k-means clustering.
To be robust enough, the model must be trained on at least 4 of Bill Hardy’s pages (4% of the book) and 25 pages not belonging to Bill (25%). All in all, we have trained the model with just under 30% of the book. After 20 epochs, the trained model can accurately perform the binary classification of pages for the whole book. Most of the time (empirically > 70%), the confusion matrix is perfect.
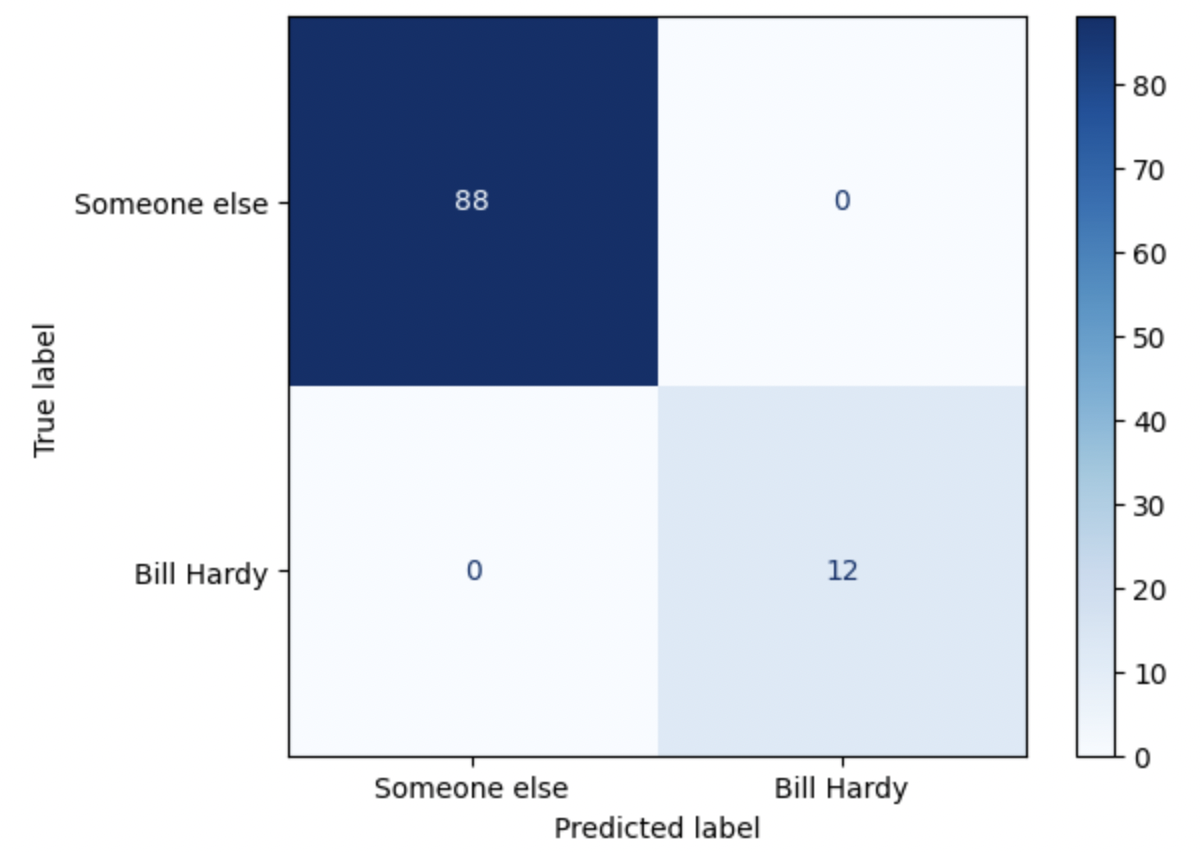
When the accuracy score is insufficient, one or two pages is/are usually misclassified (this is often true for page 96). Half of the pages are misclassified in rare cases (empirically less than 5%), resulting from a poor combination of pages from the training dataset.
We attempted to extend the approach to sentences instead of pages. The model performs more poorly, as illustrated by the following confusion matrix. This is expected, as sentences can be nonspecific (e.g., “It is somewhat too sensational,” “My watch must be my mentor”).

The way we used deep learning to classify Cain’s Jawbone pages is peculiar (using it as a pseudo-forensic tool to attach writings to a fictitious person) and nonoptimal (small dataset, therefore tiny training and test dataset; solution not officially recognized, potentially impacting the accuracy of the labels). Despite these limitations, it generated some interesting results for the classification of pages and was able in most case to correctly assign pages to Bill Hardy.
Our next step will be to attempt to do a multiclass classification. In other words, to predict to which narrator each page belonged.