Is Artificial Intelligence Suitable to Solve Cain’s Jawbone? (Part III)
All opinions herein are solely my own and do not express the views or opinions of my employer. This article contains a potential solution to Cain’s Jawbone. If you plan to solve it by yourself, stop reading it.
Part I: https://guyomel.hashnode.dev/is-artificial-intelligence-suitable-to-solve-cains-jawbone-i
Part II: https://guyomel.hashnode.dev/is-artificial-intelligence-suitable-to-solve-cains-jawbone-part-ii
We have now reached the conclusion of our initial novice examination into the role of artificial intelligence in solving—or, at the very least, aiding in the resolution of—Cain’s Jawbone. An article summarizing this research’s findings will be available on glthr.com shortly. In the meantime, we share the latest results here.
Driven by the excellent performance of the binary classification of pages belonging to one of the narrators (Bill Hardy), we tried to extend it using multiclass classification. This attempt resulted in abysmal performance, almost undistinguishable from randomness, as demonstrated by this confusion matrix (each label corresponds to a narrator).
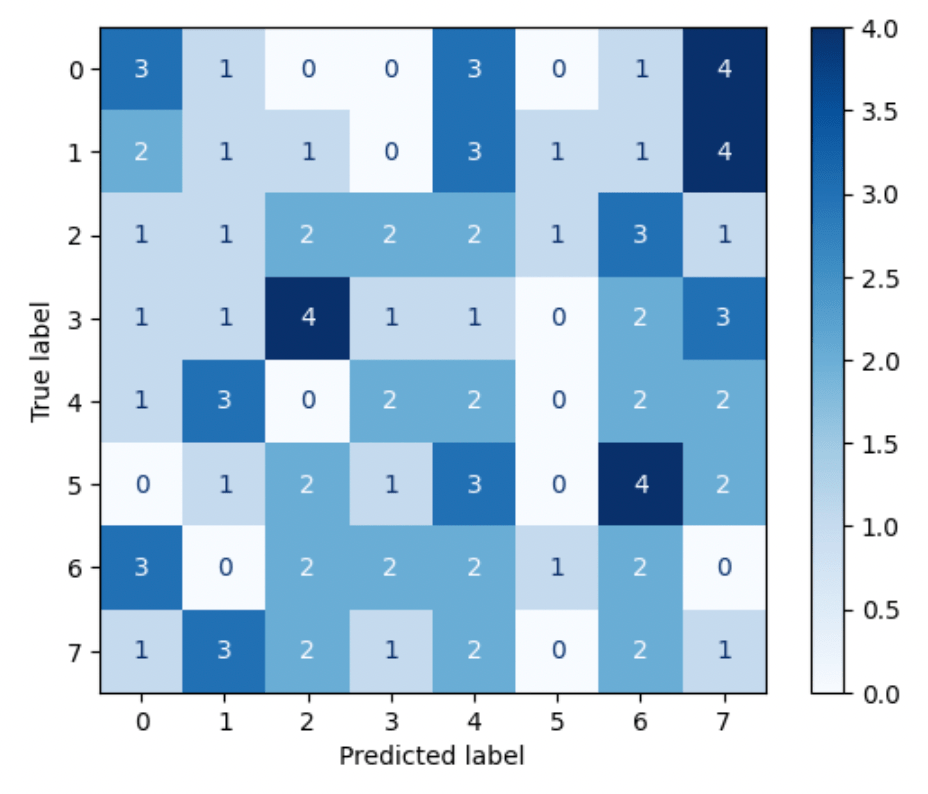
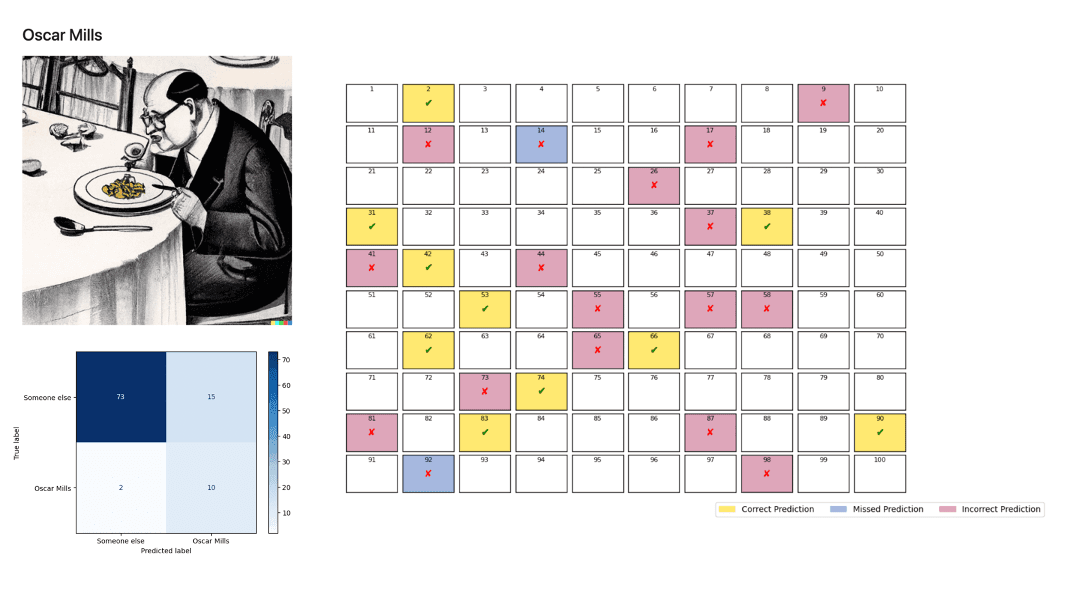
Subsequently, we performed a binary classification of all narrators to identify the root causes of this duality between excellent binary classification and poor multiclass classification. To that end, we trained a BERT model for each narrator, computed their confusion matrix, and represented the incorrect predictions.
Here are the results:
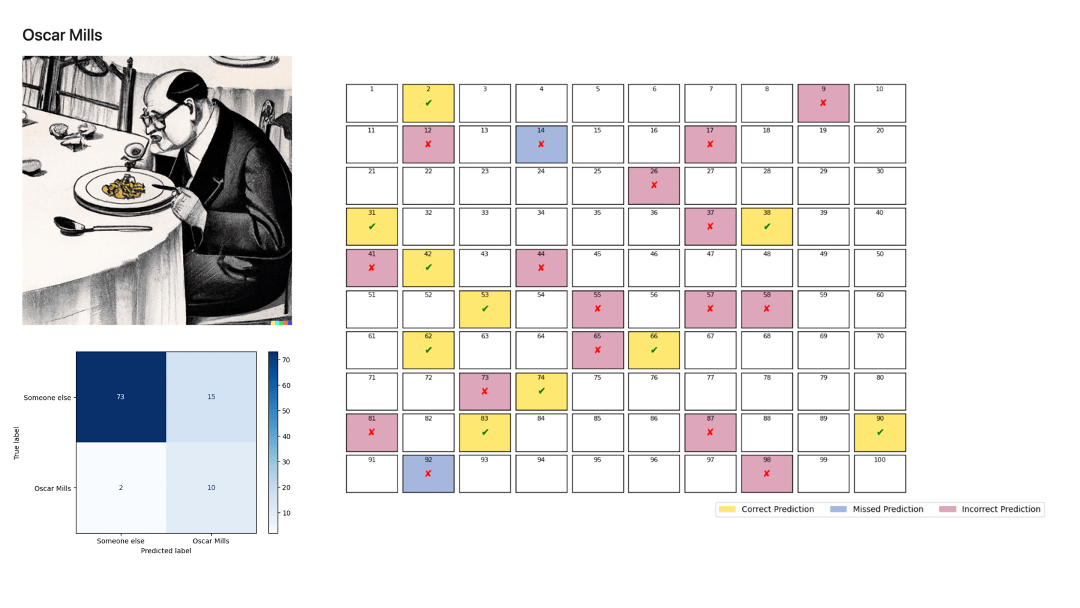
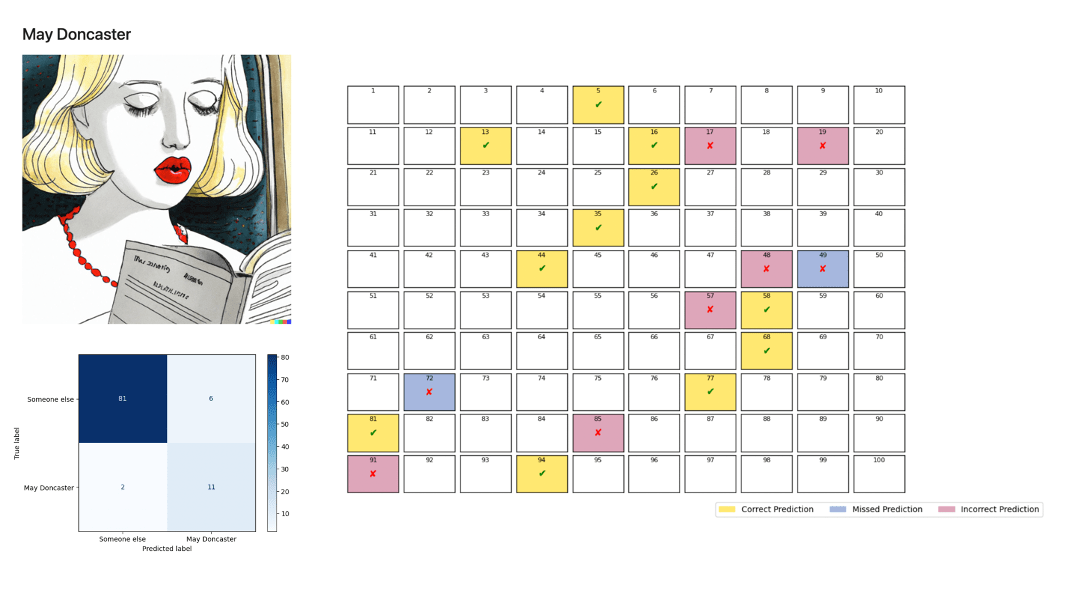

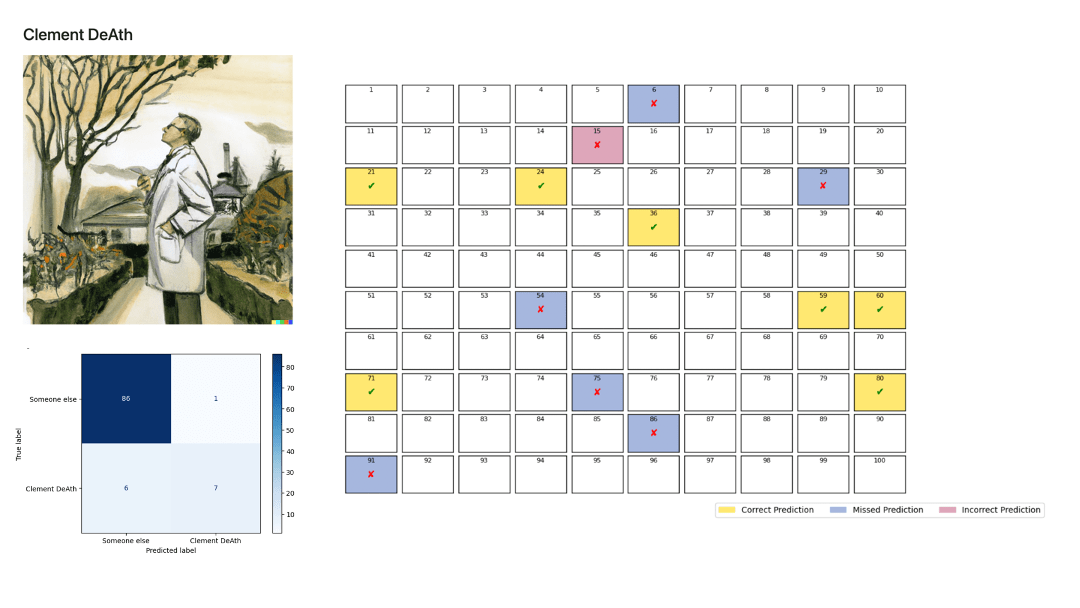
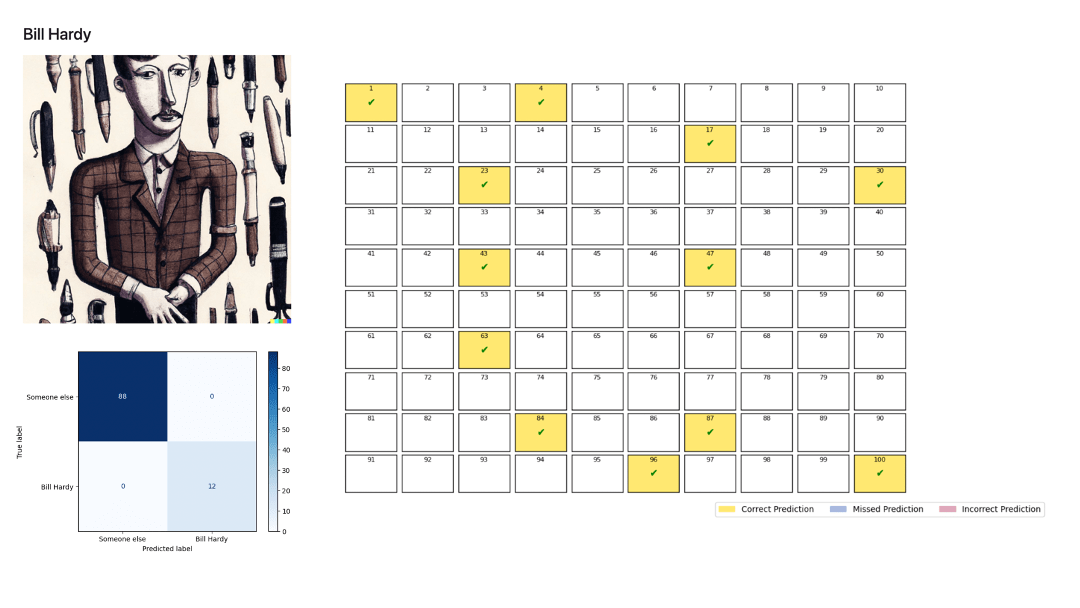
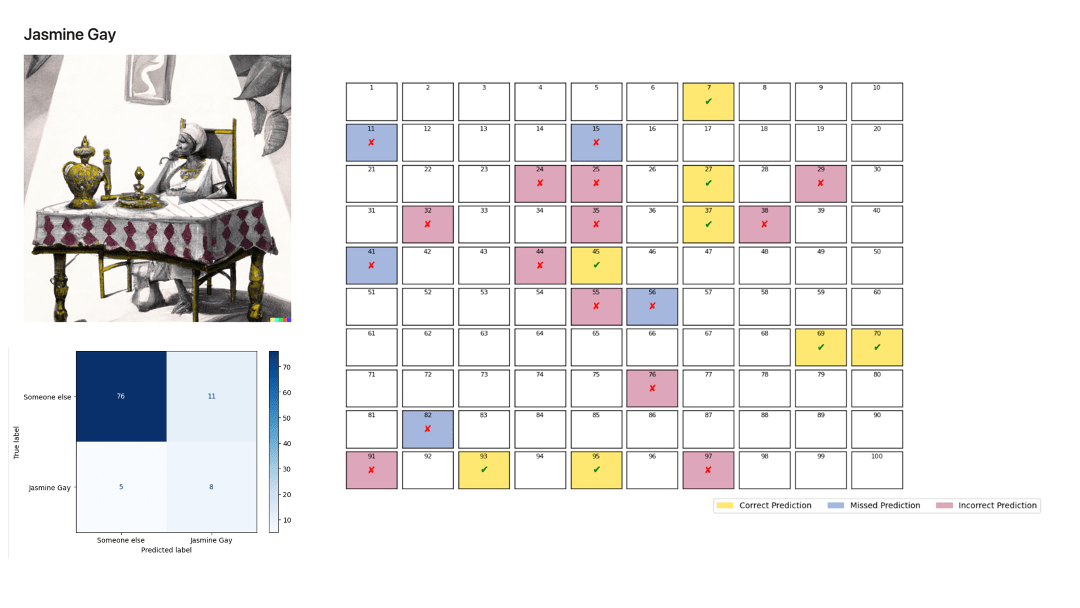

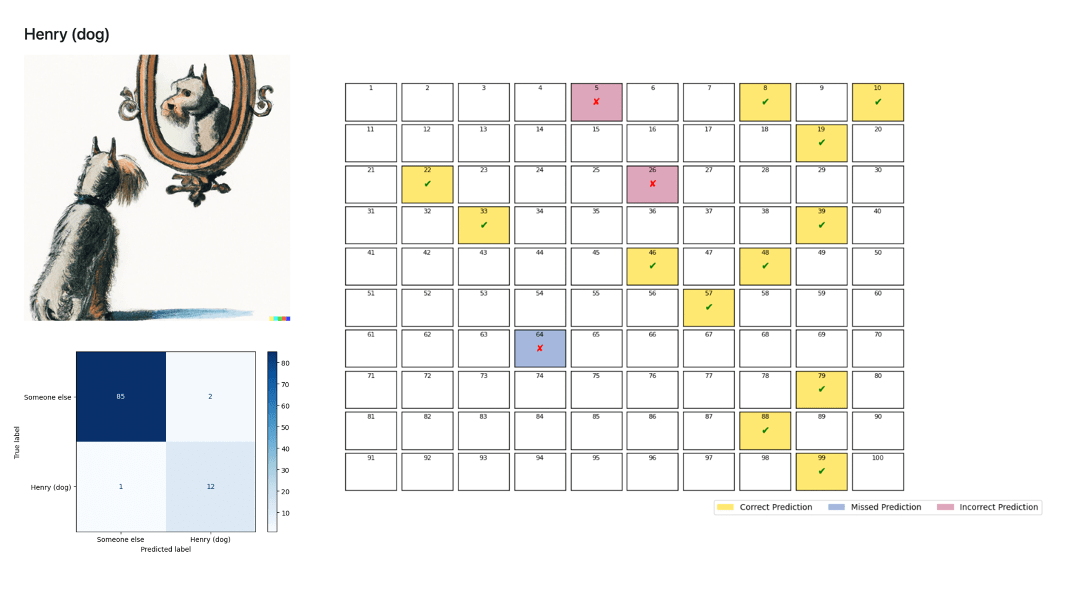
The models perform poorly for all narrators except Bill Hardy and, to a lesser extent, Henry the Dog. These results confirm the initial K-means analysis.
To explain Bill Hardy’s model’s performance, we suggest that Bill’s pages have a textual characteristic that makes them easily identifiable. This characteristic is grammatical: Bill Hardy is the only narrator who narrates in the present tense. All other narrators narrate in the past tense.
This hypothesis was evaluated by grammatically transforming some of the narratives from various authors into the present tense and altering a portion of Bill’s narratives to be in the past tense. Bill’s model erroneously labels these pages, categorizing non-Bill pages written in the present tense as belonging to Bill. It also categorizes Bill’s pages written in the past tense as not belonging to Bill.
This experiment demonstrates that we ultimately trained this model to identify whether pages are mainly written in the present tense. In other words, Bill’s model probably represents a function that produces primarily results based on the grammatical tense predominant on a given page.
The way Henry’s (or also John Walker’s) model operates is more puzzling. We have not identified an apparent textual characteristic that would explain its performance. Readers of this article may be interested in figuring it out—please let us know!
In conclusion, in the context of this project, we failed to create a model that autonomously assigns the pages to their respective narrators. Several factors may explain why.
The first reason is that this is our first machine-learning project: a more experienced reader would certainly have trained a more robust model.
However, we do not think a model can achieve the primary goal for the reasons evoked in the first article. A significant issue is the fact that most of the clues are obscure, extratextual, and highly subject to subjective interpretation. For instance:
“there was the oldest brass in England, saying: SIRE:IOHAN:DAUBERNOUN:CHIVALER:GIST:ICY:DEV:DE:SA:ALME:EYT:MERCY”, referring to Stoke d’Abernon, Surrey (extratextual reference)
“Apparently the person who slept in the lock-up at that county town on the Severn, or perhaps woke, would hear this time,” meaning 8 AM (obscure reference)
“I sat and faced the old school colours frozen there before me? Green and white and rose, grit, wisdom and reliability, the find old Head, as we called him, had quipped it,” a reference to a frozen dessert (highly subjective interpretation)
To be a suitable candidate for solving this puzzle, a model should be able to analyze and contextualize both textual and extratextual clues.
But that would not be enough.
An ideal model should also perform second-order reasoning to characterize the interactions between the narrators. That is: going beyond the mere labelling of text tokens. For instance, while a good model would identify the existence of spoonerism in Jasmine’s monologue (e.g., “Useful, courteous little chip of a bat”, page 27), a great model would be able to identify when a different narrator refers to Jasmine’s spoonerisms: “He said he’d put that right, but he couldn’t find the silly old jossers, as Jasmine might so easily have called them” (page 99).
Although we cannot categorically rule out the use of machine learning in addressing this puzzle, we would be eager to observe how others approach this issue. It is worth noting that there are still many potential avenues for exploring the application of machine learning to Cain’s Jawbone.